|
|
Быстрая обработка изображений: GPU vs CPU
Автор: Серженко Фёдор
I. Введение
За последнее десятилетие технологическое развитие графических процессоров продвинулось настолько далеко, что они могут с успехом конкурировать с традиционными решениями (например, с центральными процессорами) и применяться для широкого спектра задач, в том числе связанных с быстрой обработкой изображений.
В данной статье пойдёт речь о возможностях графического и центрального процессоров выполнять задачи быстрой обработки изображений. Мы проведём сравнение двух типов процессоров и покажем преимущества GPU перед CPU, ответим на вопрос почему обработка изображений на GPU может быть более эффективной по сравнению с аналогичными решениями на CPU.
Кроме того, мы рассмотрим часто встречающиеся заблуждения пользователей и разработчиков, которые мешают им использовать GPU для быстрой обработки изображений.
II. Особенности алгоритмов быстрой обработки изображений
Для целей нашей статьи из всего многообразия алгоритмов быстрой обработки изображений мы возьмём только те, которые обладают такими характеристиками, как локальность, возможность распараллеливания и их относительная простота. Поясним более подробно, что мы имеем в виду:
- Локальность. Каждый пиксел вычисляется на основе ограниченного количества соседей.
- Высокая способность к распараллеливанию. Каждый пиксел не зависит по данным от других обработанных пикселей, что позволяет распараллелить процесс обработки.
- 16/32-битная точность арифметики. Как правило, при обработке изображений достаточно 32-битной вещественной (floating point) арифметики для обработки и 16-битного целочисленного типа данных для хранения.
Критерии, которые важны для быстрой обработки изображений
Ключевыми критериями, важными для быстрой обработки изображений, являются:
1. Производительность
Как показывает практика, максимальной производительности можно добиться двумя способами - либо через увеличение аппаратных ресурсов, то есть с помощью наращивания количества процессоров, либо через оптимизацию программного кода. При сравнении возможностей графического процессора и центрального, в этом классе задач GPU выигрывает у CPU в соотношении цена/производительность, а реализация всего потенциала GPU возможна лишь при распараллеливании и тщательной многоуровневой оптимизации используемых алгоритмов.
2. Качество обработки изображений
Еще одним важным критерием является качество обработки изображений. Для одной и той же операции обработки изображений может существовать несколько алгоритмов, отличающихся ресурсоёмкостью и качеством получаемого результата. И тут важно понимать, что обычно ресурсоёмкие алгоритмы дают более качественный результат. Таким образом, многоуровневая оптимизация наиболее востребована для ресурсоёмких алгоритмов. После её выполнения сложные алгоритмы могут выдавать результат за приемлемое время, сравнимое со временем работы изначально быстрого, но более грубого алгоритма.
3. Латентность
Как уже говорилось выше, GPU имеет такую архитектуру, которая позволяет осуществлять параллельную обработку пикселов изображения, что приводит к сокращению латентности, или времени обработки одного изображения. Центральные процессоры обладают довольно скромными показателями латентности, поскольку в CPU параллелизм реализуется на уровне отдельных кадров, тайлов или строк изображений.
III. Ключевые отличия между GPU и CPU
1. Количество потоков на CPU и GPU
Архитектура центральных процессоров предполагает, что каждое физическое ядро на CPU может выполнять 2 потока вычислений при наличии 2 виртуальных ядер. В этом случае каждый поток выполняет инструкции независимо. В то же время количество потоков GPU в сотни раз больше, так как в этих процессорах используется программная модель SIMT (Single instruction, multiple threads). В этом случае группа потоков (обычно их 32) выполняет одну и ту же инструкцию. Таким образом, именно такую группу можно рассматривать в качестве эквивалента CPU потока, поэтому эту группу назвают истинным GPU потоком.
2. Способ реализации потоков на CPU и GPU
Ещё одним отличием GPU и CPU является то, как они скрывают латентность инструкций. CPU для этих целей использует внеочередное исполнение, а GPU использует ротацию истинных потоков, каждый раз запуская инструкции из разных потоков. Способ, используемый на GPU, является более эффективным при аппаратной реализации, но при этом необходимо, чтобы алгоритм был параллельным и нагрузка была высокой.
Из всего этого можно сделать вывод, что многие алгоритмы обработки изображений идеально подходят для реализации на GPU.
IV. Преимущества GPU над CPU
- Наши лабораторные исследования показали, что при сравнении идеально оптимизированного софта для GPU и для CPU (с применением AVX2), преимущество GPU имеет глобальный характер: пиковые производительности CPU и GPU аналогичного года производства отличаются обычно на порядок для 32- и 16-битных типов данных. Также на порядок отличается и пропускная способность подсистемы памяти. В следующих пунктах мы рассмотрим эту ситуацию подробнее.
- Если же использовать для сравнения софт для CPU без использования инструкций AVX2, то разница в производительности может достигать 50-100 раз в пользу GPU.
- Все современные GPU оснащены разделяемой памятью, которая одновременно доступна всем «вычислителям» одного мультипроцессора, что, по сути, является программно-управляемым кэшем. Он идеально подходит для алгоритмов с высокой степенью локальности. Скорость доступа к этой памяти в несколько раз превосходит возможности L1 кэша CPU.
- Ещё одной важной особенностью GPU по сравнению с CPU является то, что количество доступных регистров можно менять динамически (от 64 до 256 на один поток), тем самым позволяя снижать нагрузку на подсистему памяти. Для сравнения, в архитектурах x86 и х64 используется 16 универсальных регистров и 16 AVX регистров на один поток.
- Наличие нескольких специализированных аппаратных модулей на GPU для одновременной работы над совершенно разными задачами: аппаратная обработка изображений (ISP) на Jetson, асинхронное копирование в GPU и обратно, вычисления на GPU, аппаратное кодирование и декодирование видео (NVENC, NVDEC), тензорные ядра для нейросетей, OpenGL, DirectX, Vulkan для визуализации.
Но, как результат всех перечисленных выше преимуществ GPU перед CPU, за всё это приходится платить высокими требованиями к параллельности алгоритмов. Если для максимальной загрузки CPU достаточно десятков потоков, то для полной загрузки GPU нужны десятки тысяч потоков.
Встраиваемые (embedded) приложения
Следует помнить и о таком типе задач, как встраиваемые решения. Здесь GPU уже конкурируют со специализированными устройствами, такими как FPGA (программируемая пользователем вентильная матрица) и ASIC (интегральная схема специального назначения). Основным преимуществом GPU перед прочими решениями является их существенно большая гибкость. Для отдельных встраиваемых решений GPU может быть серьёзной альтернативой, так как мощные многоядерные процессоры не проходят по допустимым требованиям к размеру и энергопотреблению.
V. Заблуждения пользователей и разработчиков
1. У пользователей нет опыта работы с GPU, поэтому они пытаются многое сделать на CPU
Одно из ключевых заблуждений пользователей и разработчиков связано с тем, что ещё не так давно графические процессоры считались мало подходящими для высокопроизводительных вычислительных задач. Но технологии развиваются стремительно. И несмотря на то, что обработка изображений на GPU хорошо интегрируется с CPU обработкой, наилучшие результаты достигаются в тех случаях, когда быстрая обработка изображений осуществляется на GPU. На сегодняшний день есть огромное количество таких приложений.
2. Многократное копирование данных на GPU и обратно "убивает" производительность
Среди пользователей и разработчиков существует и такое предубеждение относительно обработки изображений на GPU. И здесь, как оказалось, это тоже всего лишь неверная интерпретация, поскольку надёжным решением в этом случае является реализация всей схемы обработки на GPU в рамках одной задачи. Исходные данные могут быть скопированы на GPU, а обратно на CPU отдаются только результаты расчётов. Таким образом, все промежуточные данные остаются на GPU. Кроме того, копирования могут выполняться асинхронно, в одно и то же время с вычислениями над предыдущим кадром.
3. Размер разделяемой памяти составляет 96 кБайт на каждый мультипроцессор, что очень мало
Несмотря на малый размер разделяемой памяти GPU в 96 кБайт, при экономичном подходе к управлению разделяемой памятью, этого объёма может хватить в полной мере. Именно в этом и состоит суть оптимизации ПО для CUDA/OpenCL. То есть нельзя просто перенести код с CPU на GPU, не принимая во внимание все особенности архитектуры GPU.
4. Недостаточный размер глобальной памяти GPU для решения сложных задач
Это существенный момент, который, с одной стороны, решают производители, выпуская новые видеокарты с увеличенным размером памяти. С другой стороны, возможны программные решения по управлению памятью для её повторного использования.
5. Библиотеки по обработке на CPU тоже используют параллельные вычисления
Действительно, у CPU есть возможности по параллельной работе в рамках векторных операций типа AVX и многопоточности (например, через OpenMP). Но в большинстве случаев распараллеливание происходит самым простым способом: каждый кадр обрабатывается в отдельном потоке, а сам код обработки одного кадра остаётся последовательным. Использование векторных инструкций сталкивается со сложностью написания и поддержки кода для разных архитектур, моделей процессоров и систем. Оптимизация кода в библиотеках конкретных вендоров, например, Intel IPP, находится на высоком уровне. Проблемы возникают тогда, когда нужный функционал отсутствует в библиотеках и приходится использовать сторонние открытые или проприетарные библиотеки, где оптимизация может отсутствовать.
Еще одним аспектом, который плохо сказывается на производительности массовых библиотек, является широкое распространение облачных вычислений. В большинстве случаев для разработчика значительно дешевле докупить мощности в облаке по запросу, чем заниматься развитием оптимизированных библиотек. Заказчики требуют ускорить выход готового продукта на рынок, потому разработчики вынуждены использовать относительно простые и не самые эффективные решения.
Тем не менее, современные промышленные камеры генерируют видеопотоки очень высокой интенсивности, которые часто исключают возможность передачи данных для обработки по сети в облако, поэтому для обработки видеопотока с таких камер обычно используются локальные ПК. Компьютер, используемый для вычислений, должен обладать требуемой производительностью для обработки, и, что важно по сравнению с облачным подходом, его необходимо приобрести на начальных этапах реализации решения. Производительность решения зависит как от аппаратного, так и от программного обеспечения. При планировании решения следует учитывать и то, какое аппаратное обеспечение используется. Если удаётся обойтись широко распространёнными аппаратными средствами, проблем не возникает, и можно использовать любое программное обеспечение. Как только возникает необходимость использования более дорогого оборудования, цена единицы производительности начинает быстро увеличиваться и это создает предпосылки для использования оптимизированного ПО.
Задача обработки данных с промышленных видеокамер характеризуется постоянной нагрузкой. Уровень нагрузки определяется набором применяемых алгоритмов и количеством данных в единицу времени. Система обработки изображений должна быть рассчитана на начальных этапах проекта, чтобы с гарантированным запасом справляться с данной нагрузкой, иначе обработка без потери данных будет невозможна. Это является ключевым отличием от web-систем, где нагрузка неравномерна.
VI. Заключение
Итак, подводя итоги всего вышесказанного, мы приходим к следующим выводам.
1. GPU является прекрасной альтернативой CPU для решения сложных задач по быстрой обработке изображений.
2. Производительность оптимизированных решений для обработки изображений на GPU намного выше, чем на CPU. В качестве подтверждения мысли, мы предлагаем вам обратиться к другой статье из блога Fastvideo, в которой описаны бенчмарки на разных GPU для часто используемых алгоритмов обработки и сжатия изображений.
3. GPU обладает архитектурой, благодаря которой осуществляется параллельная обработка пикселов изображения, что, в свою очередь, приводит к сокращению времени обработки одного изображения (латентности).
4. Стоимость владения системами обработки изображений на основе GPU, оказывается ниже чем у систем, использующих только CPU. Высокая производительность GPU позволяет уменьшить количество единиц оборудования в таких системах, а высокая энергоэффективность снизить потребление электричества.
5. GPU обладает необходимой гибкостью, высокой производительностью, низким энергопотреблением для того, чтобы конкурировать с узкоспециализированными решениями типа FPGA/ASIC для использования в мобильных и встраиваемых решениях.
6. Объединение возможностей CUDA/OpenCL и аппаратных тензорных ядер позволяет значительно увеличить производительность для задач с применением нейросетей.
Приложение №1
Сравнение пиковой производительности CPU и GPU на примере NVIDIA
Сравнение выполним на типе float (32-битный вещественный тип). Этот тип отлично подходит для обработки изображений. Оценивать производительность будем для одного ядра. В случае с CPU всё просто, речь идет о производительности одного физического ядра. Для GPU всё несколько сложнее. То, что принято называть у GPU ядром – это по сути своей АЛУ, или, в терминологии NVIDIA – SP (Streaming Processor). Реальными аналогом CPU ядра является стриминговый мультипроцессор (в терминологии NVIDIA, Streaming Multiprocessor, SM). Количество стриминговых процессоров в одном мультипроцессоре зависит от семейства GPU. Например, видеокарты NVIDIA Turing содержат 64 SP в одном SM, а у NVIDIA Ampere их 128. За каждый такт один SP может выполнять одну инструкцию FMA (Fused Multiply–Add). Инструкция FMA выбрана здесь для сравнения, так как она используется для реализации свёртки в фильтрах. Её целочисленный аналог называется MAD. Инструкция (один из вариантов) выполняет следующее действие: B=AX+B, где B – аккумулятор, накапливающий значения свёртки, A – коэффициент фильтра, X – значение пиксела. Сама по себе такая инструкция выполняет два операции: умножение и суммирование. Это даёт нам производительность за такт для SM: Turing - 2*64 =128 FLOP, Ampere - 2*128 = 256 FLOP
Современные CPU обладают возможностью за каждый такт выполнять 2 инструкции FMA из набора AVX2. Каждая такая инструкция содержит 8 float операндов и соответственно 16 операций (FLOP). Итого, одно CPU ядро выполняет 2*16=32 FLOP за такт.
Чтобы перейти к производительности в единицу времени, нужно умножить количество инструкций за такт на частоту устройства. В среднем, частота GPU находится в диапазоне 1.5–1.9 ГГц, а CPU при нагрузке на все ядра имеет частоту 3.5–4.5 ГГц. Инструкция FMA из набора AVX2 является сложной для CPU. При её исполнении участвует большое количество устройств и сильно возрастает тепловыделение. Это приводит к тому, что CPU вынужден снижать частоту, чтобы избежать перегрева. Для разных семейств CPU величина снижения частоты разная. Например, по этой статье можно оценить снижение до уровня 0.7 от полной. Далее будем брать коэффициент 0.8, он соответствует более новым поколениям CPU.
Условно можно считать, что CPU по частоте в 2.5 раза быстрее GPU. С учётом коэффициента снижения частоты при работе с AVX2 инструкциями получим 2.5*0.8 = 2. Итого, относительная производительность в FLOP для инструкции FMA при сравнении с CPU ядром получим: Turing SM = 128 / (2.0*32) = 2 раза, а для Ampere SM это 256 / (2.0*32) = 4 раза, т.е. один SM лучше, чем одно ядро CPU.
Оценим производительность L1 для CPU ядра. Современные СPU могут выполнять загрузку двух 256-битных регистров из кэша L1 параллельно или 64 байта за такт. GPU обладает унифицированным блоком разделаяемой памяти/L1. Производительность блока одинакова для двух архитектур и составляет 32 float за такт, или 128 байт за такт. Воспользовавшись соотношением частот, получим отношение производительностей 128 (байт за такт) / (2 (частота CPU больше GPU) * 64 (байт за такт)) = 1.
Также сравним размеры L1 и разделяемой памяти для CPU и GPU. Для CPU стандартным размером кэша данных L1 является 32 кБайт. Turing SM имеет 96 кБайт, а у Ampere SM имеется 128 кБайт разделяемой памяти.
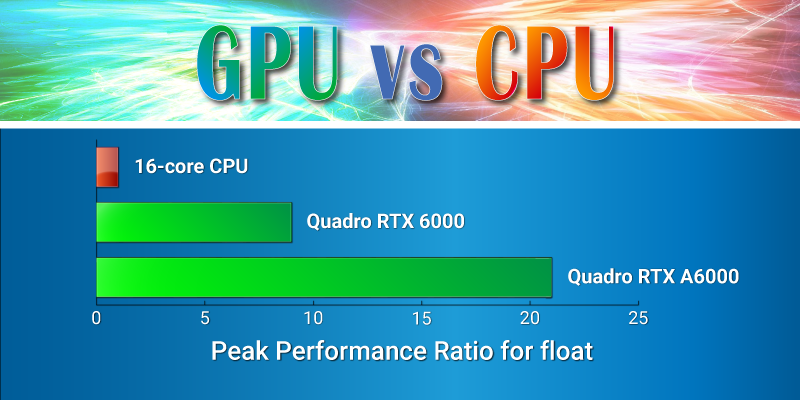
Для оценки общий производительности определимся с количеством ядер на SP. Для настольных CPU рассмотрим вариант из 16 ядер (AMD Ryzen, Intel i9), у GPU (NVIDIA Quadro RTX 6000) имеется 72 SP. Итого отношение по количеству ядер 72/16 = 4.5. Таким образом, для этой пары CPU/GPU пропускная способность L1 и разделяемой памяти отличается в 1 * 4.5 = 4.5 раза.
На основе этого рассчитаем общую производительность по float. Для топовых видеокарт Turing получаем: 4.5 (отношение по количеству ядер GPU/CPU) * 2 (отношение производительности SM к производительности одного ядра CPU) = 9 раз.
Для видеокарт Ampere (NVIDIA Quadro RTX A6000, у которой 84 SP) получаем: 4.5 (отношение по количеству ядер GPU/CPU) * 4 (отношение производительности SM к производительности одного ядра CPU) *84/72 = 21 раз.
Мы получили численную оценку, которая отражает существенное преимущество GPU над CPU как по производительности, так и по скорости доступа к быстрой памяти в расчётах, связанных с обработкой изображений.
Тут очень важно напомнить, что указанные соотношения получаются для CPU только при использовании AVX2 инструкций. В случае использовании скалярных инструкций, производительность CPU ядра снижается в 8 раз, как по арифметическим операциям, так и по скорости обращения к памяти. Поэтому для современных CPU особую важность приобретает оптимизация программного кода.
Скажем пару слов и о новым наборе AVX-512 для CPU. Это следующее поколение SIMD инструкций с увеличенной до 512 бит длиной вектора. Ожидается удвоение производительности в будущем по сравнению с AVX2. Современные версии CPU обеспечивают реальное преимущество до 1.6 раз, так как требуют ещё большего снижения частоты, чем инструкции из набора AVX2. Набор AVX-512 пока не получил широкого распространения в массовом сегменте, но это скорее всего произойдёт в будущем. Минусами этого подхода станут необходимость адаптации алгоритмов на новую длину вектора и перекомпиляция кода для поддержки.
Попробуем сравнить пропускную способность системной памяти. Тут тоже можно увидеть значительный разброс значений. Для CPU начальные цифры – это 50 ГБайт/с (2-канальный контроллер DDR4 3200) для массовых CPU. В сегменте для рабочих станций доминирует CPU с четырёхканальными контроллерами – это 100 ГБайт/с. Для серверов можно встретить CPU с 6-8 канальными контроллерами и производительностью более 150 ГБайт/с.
У GPU значение пропускной способности глобальной памяти тоже находится в широком диапазоне. Начиная от 450 ГБайт/с у модели Quadro RTX 5000, и заканчивая 1550 ГБайт/с у старшей модели A100. В итоге можно сказать, что пропускная способность в сопоставимых сегментах отличается значительно, вплоть до разницы на порядок.
Из всего вышесказанного можно сделать вывод, что GPU существенно (иногда практически на порядок) превосходит CPU, который выполняет оптимизированный код. В случае неоптимизированного для CPU кода, разница по производительности может быть ещё больше, до 50–100 раз. Все это создаёт серьёзные предпосылки для увеличения производительности в реальных задачах.
Приложение №2 - алгоритмы memory-bound и compute bound
Когда мы говорим об этих типах алгоритмов, необходимо понимать, что речь идёт о конкретной реализации алгоритма на конкретной архитектуре. У каждого процессора есть некоторая пиковая арифметическая производительность. Если реализация алгоритма может на целевом участке достигнуть пиковой производительности процессора по вычислительным инструкциям, то тогда она compute-bound, в противном случае основным ограничением станет память и реализация memory-bound.
Подсистема памяти у всех процессоров является иерархической, состоящий из нескольких уровней. Чем уровень ближе к процессору, тем он меньше по объёму и тем он быстрее. На первом уровне находится кэш данных первого уровня, а на последнем уровне оперативная память.
Алгоритм может быть изначально compute-bound на первом уровне иерархии, а затем стать memory-bound на более высоких уровнях иерархии.
Рассмотрим несколько примеров. Допустим, мы хотим сложить два массива и записать результат в третий. Можно записать это как X = Y + Z, где X, Y, Z – массивы. Допустим, мы воспользуемся инструкциями AVX для реализации на процессоре. Тогда на один элемент нам потребуется два чтения, одно суммирование и одна запись. Современный CPU может выполнить два чтения и одну запись одновременно в кэш L1. Но вместе с тем, он может выполнить и две арифметические инструкции, а мы можем воспользоваться только одной. Это значит, что алгоритм суммирования массивов является memory-bound уже на первом уровне иерархии памяти.
Рассмотрим второй алгоритм. Фильтрация изображения в окне 3×3. Фильтрация изображения основана на операции свёртки окрестности пиксела с коэффициентами фильтра. Для вычисления свёртки используется инструкция MAD (или FMA в зависимости от архитектуры). Для окна 3×3 потребуется 9 таких инструкций. Операция инструкции B = AX + B, где B – аккумулятор, накапливающий значения свёртки, A – коэффициент фильтра, X – значение пиксела. Значения A и B находятся в регистрах, а значения пиксела загружаются из памяти. В этом случае на одну инструкцию FMA требуется одна загрузка. Здесь CPU сможет за счёт двух загрузок снабжать данными два порта FMA и полностью загрузит процессор. Алгоритм можно считать compute-bound.
Давайте рассмотрим этот же алгоритм на уровне доступа к оперативной памяти. Возьмём самую экономную по памяти реализацию, когда одно чтение пиксела обновляет все окна в которые он входит. В этом случае на одну операцию чтения будет приходиться 9 инструкций FMA. Таким образом, одно ядро CPU при обработке float данных на частоте 4 ГГц потребует 2 (инструкции за такт) × 8 (float в AVX регистре) × 4 (Байта в float) × 4 (ГГц) / 9 = 28.5 ГБайт/с. Двухканальный контролер с DDR4-3200 имеет пиковую пропускную способность в 50 ГБайт/с и по расчётам он способен быть источником данных только для двух CPU ядер в этой задаче. Поэтому такой алгоритм, запущенный на 8–16 ядерном процессоре является memory-bound. Несмотря на то, что на нижнем уровне он сбалансирован.
Теперь рассмотрим этот же алгоритм при реализации на GPU. Сразу видно, что GPU имеет на уровне SM менее сбалансированную архитектуру с уклоном в вычисления. Для архитектуры Turing отношение скорости арифметических операций (во float) к скорости загрузки из Shared Memory – 2:1, для Ampere 4:1. За счёт большего количества регистров на GPU можно реализовать указанную выше оптимизацию для CPU напрямую на регистрах GPU. Это позволяет сбалансировать алгоритм даже для Ampere. И на уровне Shared Memory реализация остается compute-bound. С точки зрения памяти верхнего уровня (глобальной) расчёт для Quadro RTX 5000 (Turing) даёт следующие результаты: 64 (операций за такт) × 4 (Байт в float) × 1.7 (ГГц) / 9 = 48.3 ГБайт/с на один SM. Отношение общей пропускной способности к пропускной способности SM составит 450 / 48.3 = 9.3 раза. Общее количество SM в Quadro RTX 5000 равно 48. Т.е. и для GPU алгоритм фильтрации на высоком уровне является memory-bound.
По мере роста размера окна алгоритм становится всё более сложным и соответственно смещается в сторону compute-bound. Большинство алгоритмов обработки изображений являются memory-bound на уровне глобальной памяти. И так как пропускная способность памяти GPU во многих случаях на порядок больше чем у CPU, то это обеспечивает сопоставимый прирост производительности.
Приложение №3
Программные модели SIMD и SIMT, или почему у GPU так много потоков
Для повышения производительности CPU используются SIMD (single instruction, multiple data) инструкции. Одна такая инструкция позволяет выполнить несколько однотипных операций над вектором данных. Плюсом этого подхода является рост производительности без существенной модификации instruction pipeline. Все современные CPU, как x86, так и ARM, имеют SIMD инструкции. Минусом данного подхода является сложность программирования. Основной подход к SIMD программированию — это использование intrinsic. Intrinsic – это встроенные функции компилятора, которые содержат одну или несколько SIMD-инструкций, плюс инструкции для подготовки параметров. Intrinsic формируют низкоуровневый язык, очень близкий к ассемблеру, который крайне трудоёмок в использовании. Кроме того, для каждого набора инструкций у каждого компилятора есть свой набор Intrinsic. Выходит новый набор инструкций – нужно всё переписывать, переходим на новую платформу (с x86 на ARM) нужно переписывать, переходим на другой компилятор - опять нужно всё переписывать.
Программная модель для GPU называется SIMT (Single instruction, multiple threads). Одна инструкция синхронно исполняется в нескольких потоках. Этот подход можно считать развитием SIMD. Скалярная программная модель скрывает векторную суть машины, автоматизируя и упрощая многие операции. Именно поэтому для большинства программистов писать привычный скалярный код на SIMT проще, чем векторный на чистом SIMD.
CPU и GPU по-разному решают вопрос латентности инструкций при исполнении их на конвейере. Латентность инструкции – это через сколько тактов следующая инструкция может воспользоваться её результатами. Например, если латентность инструкции равна 3 и CPU может запускать 4 таких инструкции за такт, то за 3 такта процессор запустит 2 зависимых инструкции или 12 независимых. Чтобы избежать такого существенного простоя, все современные процессоры используют внеочередное исполнение инструкций. В этом случае процессор в заданном окне CPU анализирует зависимости инструкций и запускает независимые инструкции вне очереди.
GPU использует другой подход, основанный на многопоточности. У GPU есть pool потоков. Каждый такт выбирается один поток и из него выбирается одна инструкция, которая отправляется на исполнение. На следующем такте выбирается следующий поток и так далее. После того, как из всех потоков в pool была запущена одна инструкция, возвращаемся к первому потоку и т.д. Такой подход позволяет скрыть латентность зависимых инструкций за счёт исполнения инструкций из других потоков.
При программировании GPU можно условно выделить два уровня потоков. Первый уровень потоков отвечает за формирование SIMT. Для GPU NVIDIA – это 32 соседних потока, которые называются warp. Известно, что SM для Turing поддерживает 1024 потока. Это количество распадается на 32 настоящих потока, в рамках которых организуется SIMT исполнение. Настоящие потоки могут в один момент времени исполнять разные инструкции, в отличие от SIMT.
Таким образом, стриминговый мультипроцессор Turing – это векторная машина с размером вектора 32 и 32-мя независимыми потоками. Ядро CPU с AVX – это векторная машина с размером вектора 8 и двумя независимыми потоками.
Дополнительные материалы по теме
|